I’ve been using Unix words to solve Wordle. The first step is to install a wordlist. I’m using a PC again, so I installed WLS and noticed Ubuntu on Windows didn’t install a wordlist by default. Attempting to install the wordlist package prompts me to install one of the many wordlist packages. Since Wordle uses fairly common words, I decided to use the default American English dictionary:
sudo apt install wamerican
That gave me a list of 104,334 common English words:
$ wc -w /usr/share/dict/american-english
104334 /usr/share/dict/american-english
The wc command counts words if you pass it -w. You can get the same result in this case by using -l, which counts lines since the word lists have one word per line.
It might help to know, if you didn’t already, that Wordle uses 5-letter words, which narrows the search space considerable:
$ grep '^.....$' /usr/share/dict/american-english | wc -w
7044
grep filters lines in a file using a regular expression. In this case we want to find words with exactly 5 letters. Initially you might think to try ..... which looks for lines with 5 characters, but that includes many more words:
$ grep '.....' /usr/share/dict/american-english | wc -w
99168
The problem is this search looks for words with at least 5 letters, which is why we need to lock the pattern to starting at the beginning of the line ^ and ending at the end $.
If we use egrep we can use extended regular expressions (EREs) to make the 5-character search more explicit with .{5} instead of 5 dots:
$ egrep '^.{5}$' /usr/share/dict/american-english | wc -w
7044
This subset list includes 804 words with apostrophes such as son's, we're or who'd which aren’t going to be Wordle solutions. A simple way to filter those out is with grep’s -v option:
$ grep '^.....$' /usr/share/dict/american-english \
| grep -v "'" \
| wc -l
6240
I noticed several other American English packages, installed them and compared them by the number of 5-letter words they include:
$ for f in /usr/share/dict/american-english*; \
do \
echo `grep '^.....$' $f \
| grep -v "[']" \
| wc -w` $f ; \
done | sort -n
3589 /usr/share/dict/american-english-small
6240 /usr/share/dict/american-english
9155 /usr/share/dict/american-english-large
15250 /usr/share/dict/american-english-huge
27275 /usr/share/dict/american-english-insane
Wordle’s dictionary includes 2,309 words, but seems to include words that aren’t included in the smallest list. So I’m defaulting to the wamerican package.
There are also a handful of words with accents that Wordle isn’t likely to use. We can use the bracket regex notation to define a character set of upper and lowercase letters [A-z]. In this context, adding a ^ negates the character set and matches the characters that don’t match the letters: [^A-z]. Finally add in ' to exclude words with an apostrophe:
$ grep '^.....$' /usr/share/dict/american-english \
| grep "[^A-z']"
Dürer
Gödel
Pôrto
abbés
adiós
blasé
cafés
éclat
fêtes
króna
mêlée
outré
passé
épées
roués
sauté
étude
Some of these words could be included without the accent(s). An easy way to strip out accents is with iconv.
$ grep '^.....$' /usr/share/dict/american-english \
| grep "[^A-z']" \
| iconv -f utf8 -t ascii//TRANSLIT
Durer
Godel
Porto
abbes
adios
blase
cafes
eclat
fetes
krona
melee
outre
passe
epees
roues
saute
etude
To avoid having to use that complex command chain, I’ve put the words in a file called wordle:
$ grep '^.....$' /usr/share/dict/american-english \
| grep -v "'" \
| iconv -f utf8 -t ascii//TRANSLIT \
> wordle
Now that we have a decent set of words, let’s test it out with a recent puzzle. I started with guessing “stain”, which matched no letters at all:

According to the Wordle Bot, that left 540. By excluding all words with the letters in “stain”, I got the list down to 731:
$ grep -v '[stain]' wordle \
| wc -w
731
I didn’t need the list to find a guess that didn’t include those letters. I picked “hoped”:
![]()
Now I knew the word included an E and none of the letters in “stain” or “hopd”:
$ grep -v '[stainhopd]' wordle \
| grep e \
| wc -w
142
We also know the E is not in the 4th position, which we can filter out with another grep -v command:
$ grep -v '[stainhopd]' wordle \
| grep e \
| grep -v ...e. \
| wc -w
76
Notice I don’t need to worry about matching longer words thanks to cutting the list down to 5-letter words.
This time I used the filtered word list and I randomly picked the last word when sorted alphabetically: “wreck”.
![]()
This gave us a new letter (R), eliminated 3 more letters (“wck”), and removed words that had an R in the second position or an E in the third position. The naive way to code that is to add those letters to the grep -v command:
$ grep -v '[stainhopdwck]' wordle \
| grep e \
| grep r \
| grep -v .ree. \
| wc -w
66
As you can see, that actually increased the number of possible words. That’s because the command only eliminated words that had all three letters in those positions:
$ grep -v '[stainhopdwck]' wordle \
| grep e \
| grep r \
| grep .ree.
Greer
freer
The right way to solve this is with the inverted character set notation we used earlier:
$ grep -v '[stainhopdwck]' wordle \
| grep e \
| grep r \
| grep .[^r][^e][^e].
Berle
Berry
Beryl
Derby
Gerry
Herzl
Jerry
Kerry
Merle
Perry
Segre
Terry
berry
beryl
femur
ferry
furze
lemur
merge
merry
revue
ruble
verge
verve
I picked “ferry” more or less at random:
![]()
That left a much smaller list since I could lock in the E in the second position and eliminate R from the third position:
$ grep -v '[stainhopdwckfy]' wordle \
| grep e \
| grep r \
| grep .e[^er][^e].
Segre
lemur
revue
I should probably eliminate capitalized words from my list. With two possibilities, I got lucky and chose “lemur”:
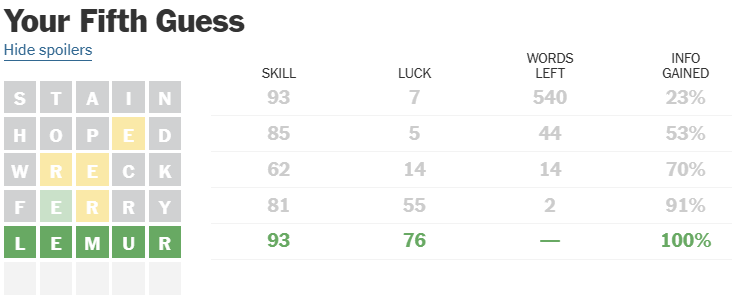
There are better ways to do this including picking words that eliminate more possibilities. But I’ve had good results with this technique.